Розвінчання міфів про OpenTelemetry: чому не варто боятися спостережуваності в традиційних середовищах
Протягом десятиліть традиційні технологічні середовища, від локальних центрів обробки даних до застарілих застосунків та промислових систем управління, були основою діяльності багатьох організацій. Ці системи перевірені в бою та глибоко вплетені в бізнес-операції, але вони також створюють унікальні виклики, коли йдеться про модернізацію інформаційних технологій, особливо спостережуваності.
Виклики впровадження спостережуваності в традиційних середовищах:
- Шумні, неструктуровані журнали ускладнюють отримання значущої інформації.
- Розрізнені дані моніторингу в різних інструментах або системах призводять до фрагментованої видимості.
- Обмежені інструменти в застарілих застосунках та системах заважають збиранню сучасних метрик та трасувань.
- Команди часто турбуються про потенційний вплив на продуктивність від додавання нових інструментів спостережуваності.
- Поєднання застарілих протоколів або апаратного забезпечення з сучасними платформами може бути складним для інтеграції.
Щоб це стало зрозумілішим, розглянемо вигадану виробничу компанію з напруженим виробничим процесом. Тут парк роботів, оснащених датчиками, передає оперативні дані через MQTT до центрального брокера. Застаріла програма реєструє виробничі події та помилки на диску, а набір серверів SQL і компʼютерів Windows підтримує виробництво, аналітику та інвентаризацію. Звучить знайомо? Це реальність для багатьох організацій, які намагаються поєднати старий і новий світи.
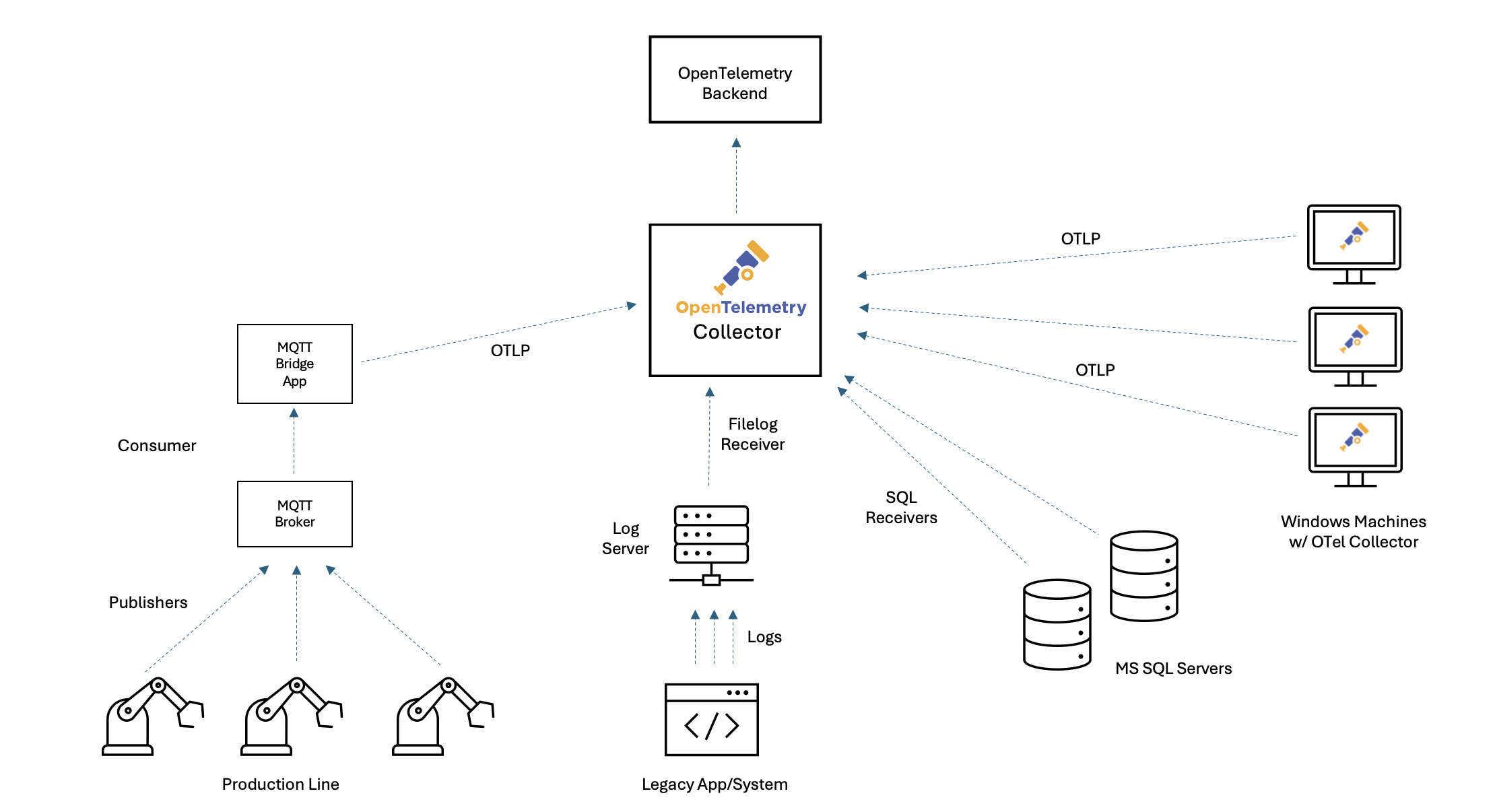
На відміну від хмарних середовищ, де інструментарій вбудований, застарілі та промислові системи покладаються на неузгоджені журнали, обмежені метрики та фрагментовані інструменти. Це призводить до недостатньої видимості, що ускладнює та уповільнює усунення несправностей, налаштування та обслуговування. Оскільки організації прагнуть підвищити надійність та прискорити трансформацію, спостережуваність більше не є «приємним бонусом» — це стратегічна необхідність. Але шлях до спостережуваності та стандартизації за допомогою OpenTelemetry часто затьмарюють стійкі міфи. Спробуємо розвіяти декілька з них!
Міф 1: Наші системи просто генерують купу непотрібних логів — тут неможливо забезпечити спостережуваність.
Подумайте про свої застарілі виробничі системи: можливо, у вас є старе обладнання або програми, які просто виводять рядок за рядком текстові журнали у файл. Ні JSON, ні структури, ні API — лише нескінченні рядки тексту. Легко припустити, що з цього безладу неможливо витягти корисну інформацію.
Чому цей міф зберігається (застарілі журнали)
У багатьох традиційних середовищах, будь то виробнича лінія, застаріла програма або промислова система управління, єдиним цифровим «сигналом», який ви можете побачити, є потік необроблених, неструктурованих файлів журналів. Для менеджера з експлуатації ці файли є надзвичайно незрозумілими. Він або вона дуже переймається конкретними несправностями; знання того, чи лінія 1 не працює через «застрягання» чи «низький тиск», визначає необхідність негайного реагування та стратегію технічного обслуговування. Але коли ці критично важливі дані поховані в неструктурованому тексті, такому як FAULT_DETECTED: Line1, Fault=Jam, вони невидимі для стандартних панелей моніторингу. Неможливо побудувати графік на основі тексту, неможливо легко створити сповіщення на основі рядка у файлі, і, звичайно, неможливо побачити тенденції в часі. Це призводить до міфу, що ці системи закриті для спостерігачів. Але завдяки сучасним інструментам спостереження, таким як OpenTelemetry, ці «непотрібні» журнали можуть стати золотою копальнею оперативної інформації.
Приклад старих рядків журналу
2026-01-04 00:39:58 | PRODUCT_COMPLETED: Line1, Count=1
2026-01-04 00:40:00 | FAULT_DETECTED: Line2, Fault=LowPressure
2026-01-04 00:40:02 | MACHINE_START: Line2
2026-01-04 00:40:07 | FAULT_DETECTED: Line2, Fault=Overheat
2026-01-04 00:40:10 | MACHINE_START: Line2
2026-01-04 00:40:14 | PRODUCT_COMPLETED: Line1, Count=1
2026-01-04 00:40:18 | MACHINE_START: Line2
2026-01-04 00:40:21 | PRODUCT_COMPLETED: Line1, Count=1
2026-01-04 00:40:27 | SENSOR_READING: Line1, Temp=83.9
2026-01-04 00:40:29 | FAULT_DETECTED: Line1, Fault=LowPressure
2026-01-04 00:40:32 | SENSOR_READING: Line1, Temp=84.7
2026-01-04 00:40:34 | PRODUCT_COMPLETED: Line1, Count=1
Як зробити цю систему спостережуваною
OpenTelemetry Collector може спостерігати за цими файлами в режимі реального часу, аналізувати події та, без необхідності внесення змін до коду застарілої програми, перетворювати їх на структуровані метрики.
Приклад конфігурації OpenTelemetry Collector
receivers:
filelog:
include: [/logs/legacy.log]
start_at: end
operators:
# 1. Загальний аналіз: захоплення позначки часу, події, рядка, а решту помістити в 'params'
- type: regex_parser
regex:
'^(?P<timestamp>.+?) \| (?P<event_type>[A-Z_]+): (?P<line>Line\d+)(?:,
(?P<params>.*))?'
timestamp:
parse_from: attributes.timestamp
layout: '%Y-%m-%d %H:%M:%S'
# 2. Конкретне отримання: шукайте "Fault=" тільки всередині 'params'
- type: regex_parser
regex: 'Fault=(?P<fault>\w+)'
parse_from: attributes.params
if: 'attributes.params != nil'
connectors:
count:
logs:
machine_events_total:
description: 'Підрахунок виробничих подій за типом, лінією та несправністю.'
attributes:
- key: event_type
default_value: 'unknown'
- key: line
default_value: 'unknown'
- key: fault
default_value: 'none' # Застосовується автоматично, якщо не виявлено несправностей
service:
pipelines:
logs:
receivers: [filelog]
exporters: [count]
metrics/generated:
receivers: [count]
exporters: [prometheus]
Як це працює
- Ланцюговий аналіз: Приймач filelog спочатку ідентифікує подію високого рівня (наприклад, FAULT_DETECTED). Потім він виконує другу, конкретну перевірку тільки для вилучення типу несправності (наприклад, «Застрягання» або «Перегрів»). Це робить конфігурацію надійною і легкою для читання.
- Генерація метрик: Конектор підрахунку перетворює ці проаналізовані журнали в метрику з назвою
machine_events_total.
Результат
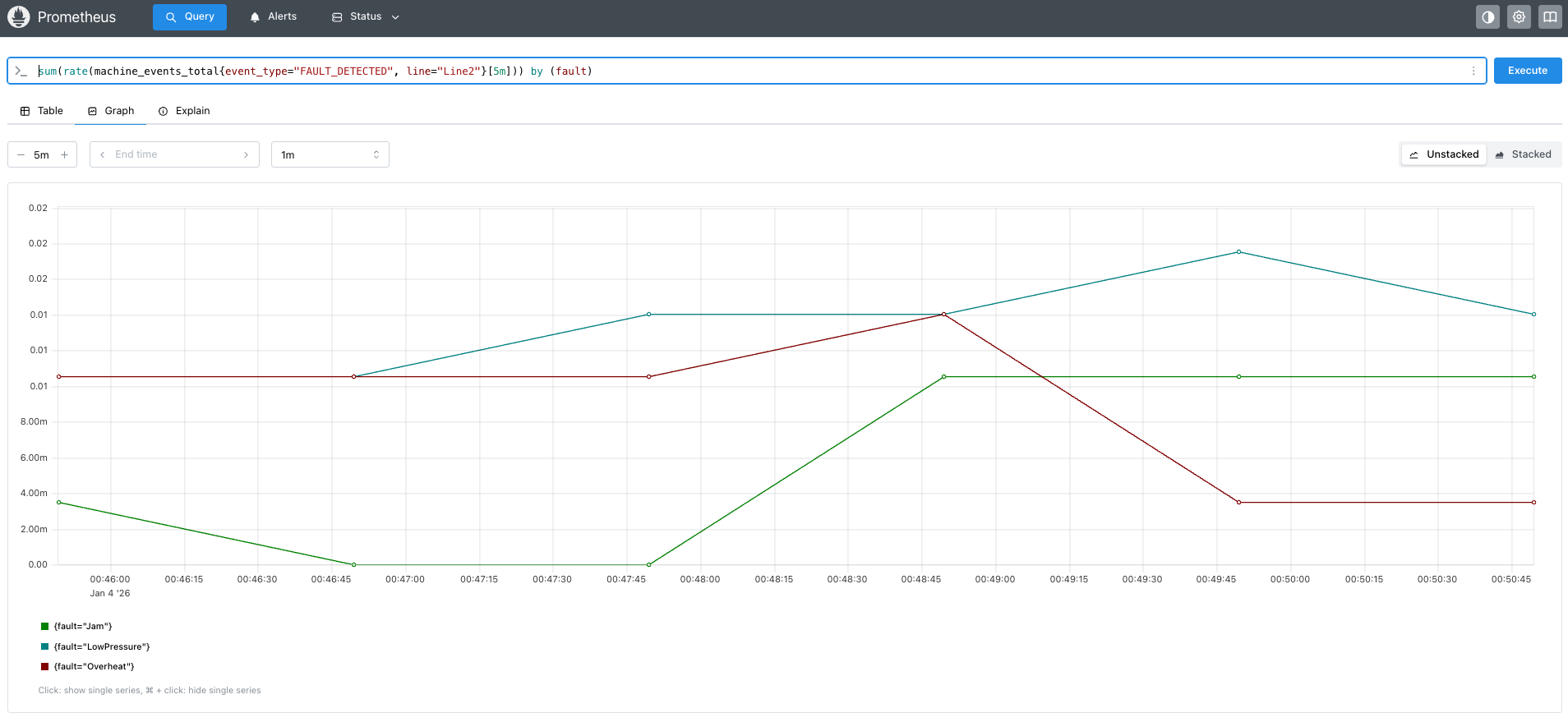
Завдяки цій конфігурації ваші старі текстові журнали стають структурованим джерелом даних, до якого можна звертатися із запитами. Тепер ваш операційний менеджер може відкрити інформаційну панель і точно побачити, скільки помилок «Застрягання» сталося на «Лінії 1» за останню годину, що сприяє прийняттю рішень на основі даних без зміни жодного рядка коду в застарілій програмі. Міф розвіяно!
Приклад інформаційної панелі в Prometheus:
Міф 2: Наші пристрої IoT публікують телеметрію в брокері MQTT, тому інтеграція з OpenTelemetry неможлива.
Наша виробнича лінія покладається на роботизовані руки та датчики, які надсилають показання до брокера MQTT (message queuing telemetry transport) — галузевого стандарту для Інтернету речей (IoT), але не є чимось, що OpenTelemetry розуміє нативно. Чи означає це, що ми залишилися без сучасного моніторингу?
Чому цей міф зберігається (інтеграція IoT і MQTT)
MQTT є основою обміну повідомленнями для незліченних промислових і IoT-середовищ, надійно передаючи дані датчиків від пристроїв до брокерів. Однак, оскільки MQTT використовує власний легкий протокол і екосистему, багато команд вважають, що їхні дані датчиків не можна легко перенести в сучасні конвеєри спостереження. Деякі брокери MQTT тепер інтегруються з OpenTelemetry, що дозволяє безпосередньо експортувати метрики та трасування за допомогою протоколу OTLP. Якщо ви використовуєте сучасного брокера з цією функцією, ви можете просто вказати своєму брокеру точку доступу OTLP вашого колектора — додатковий код не потрібен.
Якщо ваш брокер не підтримує експорт OTLP, це не є перешкодою. Ви можете використовувати легку службу-міст для реєстрації на теми MQTT і пересилання повідомлень до OpenTelemetry Collector.
Приклад даних, надісланих з датчика IoT
У нашому випадку корисне навантаження, опубліковане датчиком роботизованої руки в MQTT, може виглядати так:
{
"device_id": "robot-arm-7",
"job_id": "abc123",
"temp": 78.4,
"humidity": 32.6,
"job_start": "2025-12-19T12:00:02Z",
"job_end": "2025-12-19T12:00:05Z"
}
Це повідомлення містить інформацію про те, який пристрій його надіслав, деталі про завдання та відповідні показання датчиків.
Створення трасування та відрізків у застосунку MQTT bridge
Щоб отримати реальну наскрізну видимість (а не лише метрики), ви можете створити відрізок OpenTelemetry, що відображає тривалість і контекст кожного завдання пристрою. Це дозволяє зіставити конкретне завдання пристрою з подальшою обробкою, затримкою або помилками, що полегшує аналіз поведінки та продуктивності пристрою з часом. У складних сценаріях, наприклад, коли процеси не спілкуються через HTTP, OpenTelemetry дозволяє поширювати контекст трасування за допомогою змінних середовища, щоб подальші процеси могли повʼязати свою телеметрію з оригінальним завданням. Дізнайтеся більше в документації OpenTelemetry про поширення контексту змінних середовища.
Наступний фрагмент коду показує приклад програми MQTT bridge Python, яка слухає повідомлення датчиків, витягує час виконання завдання і створює відрізок, що відображає тривалість завдання:
import json
import datetime
import paho.mqtt.client as mqtt
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.trace.export import BatchSpanProcessor
# OpenTelemetry tracing setup
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
span_processor = BatchSpanProcessor(OTLPSpanExporter(endpoint="http://collector:4318/v1/traces"))
trace.get_tracer_provider().add_span_processor(span_processor)
def on_message(client, userdata, msg):
payload = json.loads(msg.payload.decode())
job_start = datetime.datetime.fromisoformat(payload["job_start"].replace("Z", "+00:00"))
job_end = datetime.datetime.fromisoformat(payload["job_end"].replace("Z", "+00:00"))
span = tracer.start_span(
"robotic_job",
start_time=job_start.timestamp(),
)
try:
span.set_attribute("device_id", payload["device_id"])
span.set_attribute("job_id", payload["job_id"])
span.set_attribute("temperature", payload["temp"])
span.set_attribute("humidity", payload["humidity"])
# ...additional processing...
finally:
span.end(end_time=job_end.timestamp())
# Set up MQTT client
client = mqtt.Client()
client.on_message = on_message
client.connect("mqtt-broker", 1883)
client.subscribe("production/robot-arms")
client.loop_forever()
Приклад відрізка в Jaeger:
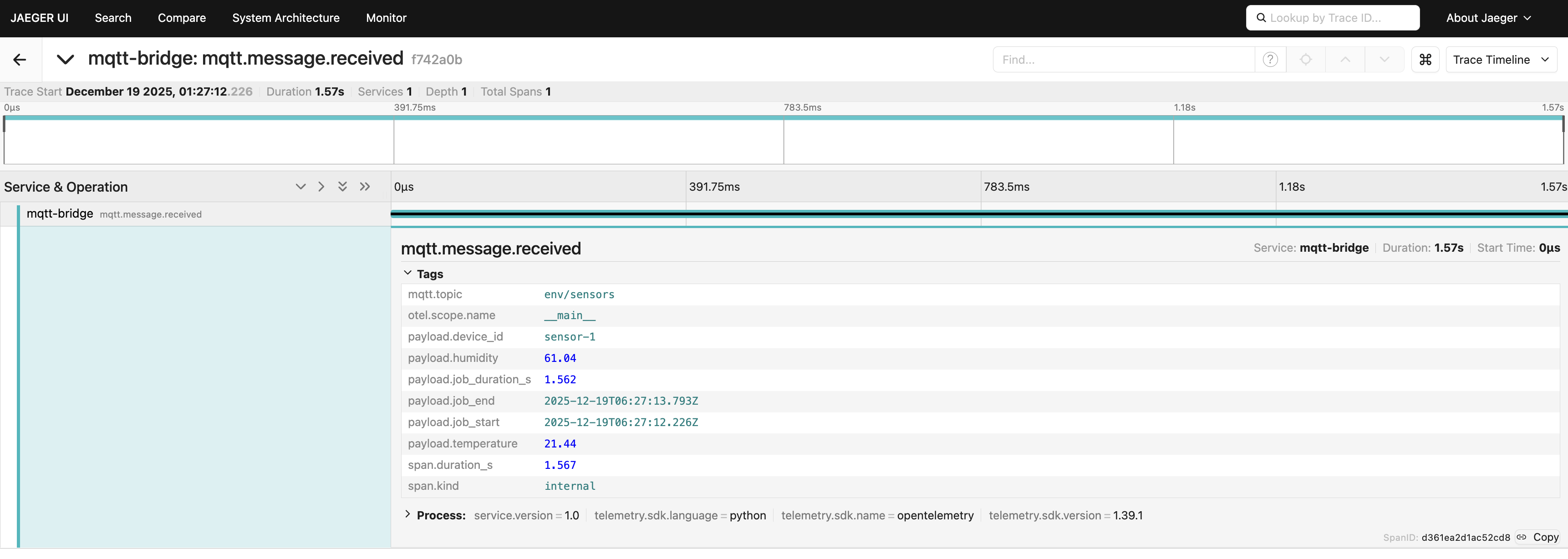
У чому тут секрет?
Явно вказавши start_time=job_start.timestamp() (і, за бажанням, end_time), відрізок точно відстежує реальне виконання завдання, навіть якщо повідомлення обробляється пізніше. Це дає вам точні трасування, які можна переглядати і які точно показують, коли відбулося кожне завдання і скільки часу воно зайняло на різних пристроях, етапах обробки та бекендах.
У вас є кілька варіантів перетворення даних датчиків IoT у метрики для інформаційних панелей та сповіщень:
Видавайте метрики безпосередньо з вашого застосунку-містка: ви можете використовувати API метрик OpenTelemetry для надсилання власних метрик (таких як температура, вологість або тривалість завдання) разом із відрізками або замість них.
Написати спеціальний процесор: Створіть власний процесор OpenTelemetry Collector, який отримує метрики з вхідних відрізків, а потім видобуває значення з атрибутів відрізків.
Використовуйте свій бекенд спостережуваності: Багато сучасних бекендів можуть генерувати метрики з атрибутів відрізків, що дозволяє легко перетворити телеметрію вашого завдання на практичні метрики, які можна шукати, з мінімальними додатковими зусиллями.
Висновок
Якщо ваш брокер MQTT підтримує OpenTelemetry, використовуйте вбудований експорт OTLP для безперебійної інтеграції. Якщо ні, проста програма-міст може перетворити потоки даних ваших датчиків і подій на повні дані спостережуваності. Сучасні бекенди спостережуваності роблять це ще простішим, дозволяючи отримувати метрики з атрибутів відрізків, завдяки чому ви можете перейти від сигналу IoT до значущої інформації з мінімальними зусиллями. А якщо вам потрібна ще глибша інтеграція або спеціальна обробка, ви можете створити власний приймач MQTT безпосередньо у вашому Collector — див. посібник OpenTelemetry щодо власних приймачів. Міф розвіяно!
Міф 3: середовища Windows і SQL Server несумісні з спостережуваністю.
Компʼютери з Windows і сервери SQL Server є основою нашої діяльності, на них виконуються всі завдання, від аналітики до інвентаризації. Проте багато хто вважає, що ці платформи просто недоступні для сучасних відкритих інструментів спостережуваності.
Чому цей міф зберігається (Windows і SQL Server)
Існує поширена думка, що моніторинг і спостережуваність можливі лише в хмарних або Linux-системах, що залишає класичні сервери Windows і робочі навантаження SQL Server поза межами досяжності. Насправді OpenTelemetry Collector підтримує обидва середовища за допомогою спеціальних приймачів, які вимагають мінімальної конфігурації. Розберімось.
Спостереження за SQL Server за допомогою OpenTelemetry Collector
Багато організацій покладаються на бази даних SQL Server для виробництва, аналітики або інвентаризації. За допомогою приймача sqlserver OpenTelemetry Collector ви можете безпосередньо збирати показники стану та продуктивності, не потребуючи агентів на хостах вашої бази даних. Нижче наведено приклад конфігурації, що показує, як це налаштувати:
receivers:
sqlserver/sql1:
collection_interval: 30s
username: oteluser
password: YourStrong!Passw0rd
server: sql-server-1
port: 1433
sqlserver/sql2:
collection_interval: 30s
username: oteluser
password: YourStrong!Passw0rd
server: sql-server-2
port: 1433
service:
pipelines:
metrics/regular:
receivers: [sqlserver/sql1, sqlserver/sql2]
exporters: [prometheus]
Що це дає для моніторингу SQL Server
Колектор регулярно збирає ключові показники SQL Server (зʼєднання, пул буферів, блокування, швидкість обробки пакетів тощо) і передає їх до серверів спостереження.
Спостереження за компʼютерами Windows за допомогою приймача лічильників продуктивності Windows
Класичні хости Windows досі використовуються в багатьох виробничих і керівних середовищах. Приймач лічильників продуктивності Windows (частина дистрибутиву OpenTelemetry Collector Contrib) дозволяє збирати широкий спектр системних, програмних або користувацьких показників безпосередньо з реєстру Windows за допомогою вбудованого інтерфейсу PDH. Нижче наведено приклад конфігурації для легкого агента, що працює на компʼютері з Windows і пересилає свої дані до центрального колектора:
receivers:
windowsperfcounters:
collection_interval: 30s
metrics:
processor.time.total:
description: Total CPU active and idle time
unit: '%'
gauge:
memory.committed:
description: Committed memory in bytes
unit: By
gauge:
perfcounters:
- object: 'Processor'
instances: ['_Total']
counters:
- name: '% Processor Time'
metric: processor.time.total
- object: 'Memory'
counters:
- name: 'Committed Bytes'
metric: memory.committed
exporters:
otlp:
endpoint: 'central-collector:4317'
service:
pipelines:
metrics:
receivers: [windowsperfcounters]
exporters: [otlp]
Що це дає для компʼютерів з Windows
Ви можете збирати дані про використання процесора, памʼяті, диска та будь-які власні лічильники Windows, перетворюючи навіть десятирічні системи на першокласні обʼєкти спостереження. Приймач є надійним: якщо лічильник відсутній, він реєструє попередження, але продовжує збирати всі доступні метрики.
Підсумок
OpenTelemetry Collector обʼєднує дані зі старих журналів, потоків MQTT, баз даних SQL Server і навіть класичних хостів Windows, розвінчуючи міф про те, що спостережуваність призначена тільки для нових або хмарних систем. За допомогою правильної конфігурації все ваше середовище, незалежно від його віку та фрагментованості, може отримати корисну інформацію в режимі реального часу для забезпечення надійності, усунення несправностей та оптимізації продуктивності.
Приклади в цій публікації показують, що не тільки можливо, але й реально обʼєднати десятирічні журнали, промислову телеметрію та класичну інфраструктуру Microsoft у сучасний стек спостережуваності. Вам не потрібно все замінювати; ви можете розбудовувати те, що вже маєте, поступово впроваджувати інструменти та отримувати нову користь від систем, які раніше були непрозорими.
Розвінчуючи ці міфи, ми бачимо, що кожне середовище, незалежно від того, наскільки воно традиційне або складне, має потенціал стати спостережуваним, стійким і готовим до цифрової трансформації. OpenTelemetry пропонує гнучкий, відкритий стандарт, який росте разом з вами, дозволяючи модернізуватися у власному темпі.
Всі міфи розвінчано. Видимість досягнуто. Ваше традиційне середовище готове до майбутнього. Настав час перетворити інформацію на дії!