Як Mastodon використовує колектори OpenTelemetry у своїй роботі
На початку 2025 року, OpenTelemetry Developer Experience SIG опублікувала результати свого першого опитування спільноти. Одне з найголовніших побажань було цілком очевидним: команди хочуть бачити більше реальних прикладів того, як SDK OpenTelemetry та OpenTelemetry Collector фактично використовуються у роботі.
Щоб заповнити цю прогалину, SIG почала збирати історії безпосередньо від кінцевих користувачів — з різних галузей, архітектур та компаній різного розміру. Ця публікація відкриває нову серію, присвячену саме реальним історіям організацій, і розпочинається з невеликого, але надзвичайно складного випадку.
У цій першій історії йдеться про Mastodon — некомерційну організацію, що працює на глобальному рівні з надзвичайно невеликою командою.
Коротко про Mastodon
Mastodon — це відкрита, побудована на вільному програмному забезпеченні, децентралізована соціальна мережа, якою керує неприбуткова організація.
Децентралізація тут не є маркетинговим терміном; це основний архітектурний принцип. Будь-хто може запустити власний сервер Mastodon, і ці незалежно керовані сервери взаємодіють за допомогою відкритих протоколів у рамках того, що називається Fediverse — федеративної мережі незалежних соціальних платформ, які спілкуються одна з одною за допомогою стандартизованих протоколів, таких як ActivityPub. Подібно до електронної пошти, користувачі можуть спілкуватися між різними екземплярами незалежно від того, хто ними керує.
Ця філософія формує не лише рішення щодо функцій Mastodon, але й підхід до спостережуваності.
Організаційна структура
Вся організація Mastodon складається приблизно з 20 осіб, а інфраструктура спостережуваності (включаючи OpenTelemetry Collector) управляється одним інженером.
Незважаючи на невеликий розмір команди, Mastodon експлуатує два великі, робочі екземпляри Mastodon:
Працює на Kubernetes з автомасштабуванням від 9 до 15 вузлів (16 ядер, 64 ГБ ОЗП кожен). Масштаб веб-фронтенду коливається між 5 і 20 подами, тоді як різні пули виконавчих процесів Sidekiq масштабуються від 10 до 40 подів. В середньому, mastodon.social має 70–80 подів, що працюють одночасно. Ця платформа обслуговує до 300 000 активних користувачів на день і опрацьовує приблизно 10 мільйонів запитів на хвилину.
Працює на Kubernetes з автомасштабуванням від 3 до 6 вузлів (8 ядер, 32 ГБ ОЗП кожен). Масштаб веб-фронтенду коливається від 3 до 10 подів, тоді як пул виконавчих процесів Sidekiq масштабуються від 5 до 15 подів, що в середньому дає 20–30 подів. Цей екземпляр працює на меншому, але все ще значному масштабі.
З таким обмеженим операційним ресурсом, простота та надійність є обовʼязковими.
Впровадження OpenTelemetry: свобода вибору, закладена в самій концепції
Оскільки Mastodon є відкритим програмним забезпеченням і призначений для запуску іншими, команда хотіла рішення для телеметрії, яке зберігало б свободу оператора.
OpenTelemetry стало стандартом, оскільки дозволяє кожному оператору сервера Mastodon самостійно вирішувати, як, чи взагалі, збирати телеметричні дані.
Використовуючи просту конфігурацію через змінні середовища, оператори можуть обирати:
- Надсилати телеметрію безпосередньо до бекенду спостережуваності (використовуючи лише конфігурацію Ruby SDK)
- Маршрутизувати телеметрію через OpenTelemetry Collector
- Повністю відключити телеметрію
Основна організація Mastodon не відстежує, як зовнішні екземпляри забезпечують спостережуваність. Важливо, щоб передані телеметричні дані суворо відповідали семантичним домовленостям OpenTelemetry, що робить її придатною для використання скрізь.
Цей підхід уникає використання специфічних моделей даних постачальників і забезпечує сумісність з ширшою екосистемою OpenTelemetry — без необхідності Mastodon підтримувати власні конвенції.
Архітектура колекторів: один на простір імен, не більше
Архітектура Collector у Mastodon навмисно мінімалістична.
Один OpenTelemetry Collector на простір імен Kubernetes обробляє всі сигнали телеметрії: трасування, метрики та логи. Немає окремих рівнів шлюзів та агентів, складних рівнів маршрутизації та спеціальних інструментів розгортання.
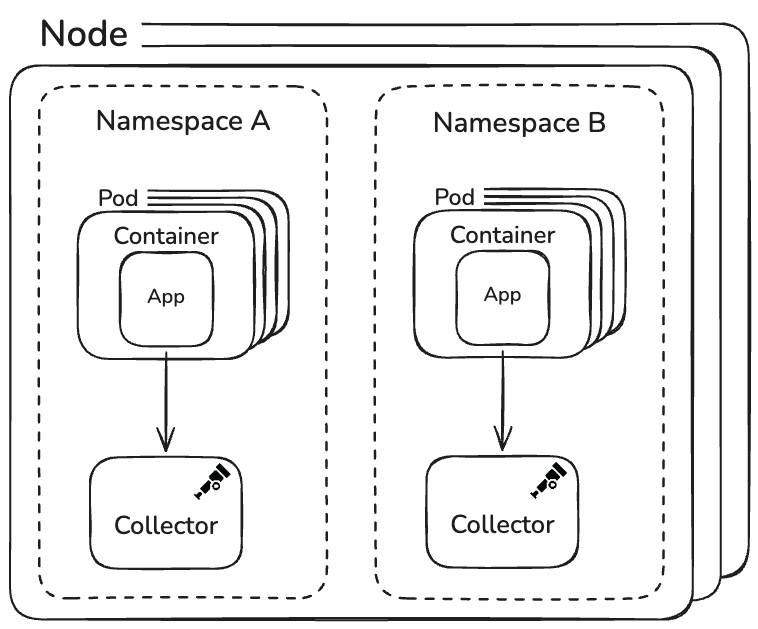
З огляду на масштаб і трафік, цього виявилося більш ніж достатньо.
Під час інтервʼю Тім Кемпбелл, інженер з розробки програмного забезпечення в Mastodon, поділився, що за ~2 роки використання Collector вони ніколи не стикалися з жодною проблемою.
“На моє здивування, і на моє дуже приємне здивування, я не зіткнувся з жодною проблемою. Оскільки ми використовуємо оператор Kubernetes для цього, якщо коли-небудь виникне якась проблема, він просто перезапуститься автоматично. Принаймні, що стосується фактичних трасувань і логів у Datadog, я не бачив жодних прогалин. Що стосується памʼяті та процесів, все залишалося абсолютно стабільним у межах встановлених нами обмежень.”
Розгортання та управління життєвим циклом
Щоб зменшити операційне навантаження до мінімуму, Mastodon покладається на:
- OpenTelemetry Operator для Kubernetes
- Argo CD для розгортання та просування на базі Git
Кожен Collector визначається як власний ресурс OpenTelemetryCollector. Звідти Kubernetes автоматично обробляє узгодження, перезапуски та управління життєвим циклом.
“В основному нам потрібно лише створити yaml-файл для кожного обʼєкта
OpenTelemetryCollector, який ми хочемо створити, і Argo автоматично розгорне/оновить те, що нам потрібно.”
Ця модель забезпечує:
- Декларативну конфігурацію
- Автоматичне відновлення у разі збою
- Повну можливість аудиту завдяки історії Git
Варто зазначити, що Mastodon не встановлює суворі обмеження на CPU або памʼяті для подів Collector. На практиці споживання ресурсів залишалося незначним порівняно з рештою платформи.
Управління трафіком через вибірку
Замість того щоб покладатися на обмеження ресурсів, Mastodon контролює накладні витрати на спостережуваність переважно через вибірку наприкінці.
- На mastodon.social вибірка успішних трасувань становить приблизно 0,1%, що призводить до збору лише кількох десятків трасувань на хвилину, незважаючи на надзвичайно високий трафік.
- На mastodon.online вибірка трохи більш ліберальна, але дотримується тих самих принципів.
- Всі трасування помилок завжди збираються, забезпечуючи повну видимість у випадках збоїв.
Цей підхід дозволяє зберігати обсяг даних передбачуваним, одночасно зберігаючи високоякісні діагностичні дані.
Конфігурація: оригінальна, але мінімалістична
Mastodon використовує дистрибутив OpenTelemetry Collector Contrib, головним чином для зручності — він включає все необхідне без потреби у створенні власних збірок.
Конфігурація зосереджена на:
- Імпорті даних OTLP для всіх сигналів
- Розширенні метаданих Kubernetes
- Виявленні ресурсів
- Вибірці наприкінці
- Перетворенні для сумісності з бекендом
Повна робоча конфігурація наведена нижче для ознайомлення (її також можна переглянути на otelbin):
apiVersion: opentelemetry.io/v1beta1
kind: OpenTelemetryCollector
metadata:
name: mastodon-social
namespace: mastodon-social
spec:
nodeSelector:
joinmastodon.org/property: mastodon.social
env:
- name: DD_API_KEY
valueFrom:
secretKeyRef:
name: datadog-secret
key: api-key
- name: DD_SITE
valueFrom:
secretKeyRef:
name: datadog-secret
key: site
config:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
cors:
allowed_origins:
- 'http://*'
- 'https://*'
processors:
batch: {}
resource:
attributes:
- key: deployment.environment.name
value: 'production'
action: upsert
- key: property
value: 'mastodon.social'
action: upsert
- key: git.commit.sha
from_attribute: vcs.repository.ref.revision
action: insert
- key: git.repository_url
from_attribute: vcs.repository.url.full
action: insert
k8sattributes:
auth_type: 'serviceAccount'
passthrough: false
extract:
metadata:
- k8s.namespace.name
- k8s.pod.name
- k8s.pod.start_time
- k8s.pod.uid
- k8s.deployment.name
- k8s.node.name
labels:
- tag_name: app.label.component
key: app.kubernetes.io/component
from: pod
pod_association:
- sources:
- from: resource_attribute
name: k8s.pod.ip
- sources:
- from: resource_attribute
name: k8s.pod.uid
- sources:
- from: connection
resourcedetection:
detectors: [system]
system:
resource_attributes:
os.description:
enabled: true
host.arch:
enabled: true
host.cpu.vendor.id:
enabled: true
host.cpu.family:
enabled: true
host.cpu.model.id:
enabled: true
host.cpu.model.name:
enabled: true
host.cpu.stepping:
enabled: true
host.cpu.cache.l2.size:
enabled: true
transform:
error_mode: ignore
# Proper code function naming
trace_statements:
- context: span
conditions:
- attributes["code.namespace"] != nil
statements:
- set(attributes["resource.name"],
Concat([attributes["code.namespace"],
attributes["code.function"]], "#"))
# Proper kubernetes hostname
- context: resource
conditions:
- attributes["k8s.node.name"] != nil
statements:
- set (attributes["k8s.node.name"],
Concat([attributes["k8s.node.name"], "k8s-1"], "-"))
metric_statements:
- context: resource
conditions:
- attributes["k8s.node.name"] != nil
statements:
- set (attributes["k8s.node.name"],
Concat([attributes["k8s.node.name"], "k8s-1"], "-"))
log_statements:
- context: resource
conditions:
- attributes["k8s.node.name"] != nil
statements:
- set (attributes["k8s.node.name"],
Concat([attributes["k8s.node.name"], "k8s-1"], "-"))
attributes/sidekiq:
include:
match_type: strict
attributes:
- key: messaging.sidekiq.job_class
actions:
- key: resource.name
from_attribute: messaging.sidekiq.job_class
action: upsert
tail_sampling:
policies:
[
{
name: errors-policy,
type: status_code,
status_code: { status_codes: [ERROR] },
},
{
name: randomized-policy,
type: probabilistic,
probabilistic: { sampling_percentage: 0.1 },
},
]
connectors:
datadog/connector:
traces:
compute_stats_by_span_kind: true
exporters:
datadog:
api:
site: ${DD_SITE}
key: ${DD_API_KEY}
traces:
compute_stats_by_span_kind: true
trace_buffer: 500
service:
pipelines:
traces/all:
receivers: [otlp]
processors:
[
resource,
k8sattributes,
resourcedetection,
transform,
attributes/sidekiq,
batch,
]
exporters: [datadog/connector]
traces/sample:
receivers: [datadog/connector]
processors: [tail_sampling, batch]
exporters: [datadog]
metrics:
receivers: [datadog/connector, otlp]
processors:
[resource, k8sattributes, resourcedetection, transform, batch]
exporters: [datadog]
logs:
receivers: [otlp]
processors:
[
resource,
k8sattributes,
resourcedetection,
transform,
attributes/sidekiq,
batch,
]
exporters: [datadog]
Тримаємо руку на пульсі
Mastodon зазвичай оновлює OpenTelemetry Collector протягом дня або двох після кожного випуску.
«Усе задокументовано, а всі зміни, що впливають на сумісність, детально описано», — зазначив Тім, високо оцінивши чіткість опису оновлення.
Хоча часті випуски іноді вводять зміни, що порушують сумісність, команда розглядає це як ознаку здорового та активного розвитку — за умови, що всі залишаються в курсі.
Уроки та проблемні моменти
Найскладнішою частиною шляху було просто почати. Розуміння того, як компоненти Collector взаємодіють між собою, вимагало часу, особливо для команди без спеціалістів з спостережуваності. Нещодавно найбільша складність виникла при використанні процесора transform на складному рівні, особливо при адаптації атрибутів span для вимог до іменування конкретного бекенду.
transform:
error_mode: ignore
# Правильне іменування функцій коду
trace_statements:
- context: span
conditions:
- attributes["code.namespace"] != nil
statements:
- set(attributes["resource.name"], Concat([attributes["code.namespace"],
attributes["code.function"]], "#"))
У правилі процесора transform вище вони налаштували умову для встановлення resource.name (атрибут, специфічний для Datadog) на значення code.namespace#code.function. З цим налаштуванням, коли span надходив на бекенд, він міг зіставлятись з іменем, яке вони визначили. Незважаючи на круту криву навчання, загальний досвід перевищив очікування.
«Ви можете робити практично все, що забажаєте. Це перевищило мої очікування. Все працює досить добре.»
Надійність і гнучкість — ось чому Mastodon продовжує використовувати OpenTelemetry Collector у роботі.
Поради для малих команд
На основі досвіду Mastodon можна виділити кілька уроків:
- Тримайте архітектуру простою: один Collector може виконати багато завдань
- Спирайтеся на оператори Kubernetes для управління життєвим циклом
- Використовуйте вибірку для контролю витрат
- Дотримуйтесь семантичних домовленостей щоб уникнути довгострокової залежності
- Часто оновлюйтеся щоб зменшити біль від змін, що порушують сумісність
Що далі
Історія Mastodon показує, що навіть дуже мала команда може успішно експлуатувати OpenTelemetry Collectors, на глобальному рівні, без значного операційного навантаження.
Це лише перша історія в серії.
У наступних публікаціях ми розглянемо, як середні та великі організації розгортають і експлуатують OpenTelemetry Collector, керують інструментуванням у різних сервісах і як їхні виклики і рішення змінюються зі збільшенням масштабу.
Якщо ви використовуєте OpenTelemetry у роботі і хочете поділитися своїм досвідом, приєднуйтесь до каналу CNCF #otel-devex у Slack. Ми будемо раді почути вашу історію і дізнатися, як ми можемо продовжувати покращувати досвід розробників OpenTelemetry разом.