Кардинальність метрик OBI
Кардинальність метрик OBI значною мірою залежить від розміру та складності інструментованого середовища, тому неможливо надати просту та точну формулу. У цьому документі зроблено спробу наблизити кардинальність метрик, які можуть бути отримані за допомогою стандартної інсталяції OBI. Він поділений на кілька розділів для кожного типу метрик, які може генерувати OBI, оскільки кожну групу метрик можна вибірково вмикати або вимикати.
Для простоти в наведених нижче формулах передбачається наявність одного кластера. Ви повинні помножити кардинальність для кожного з ваших кластерів.
Термінологія
Перед продовженням слід уточнити деякі терміни, які можуть бути неясними або підлягати тлумаченню:
- Instance: це кожна ціль інструментування. У метриках на рівні застосунків це буде екземпляр служби або клієнта. У Kubernetes це буде Pod. Екземпляр застосунку може працювати в кількох процесах. У метриках на рівні мережі кожен екземпляр — це екземпляр OBI, який інструментує всі мережеві потоки на даному хості.
- Instance Owner: у Kubernetes більшість екземплярів (Pod) мають ресурс-власник. Іноді ви можете віддати перевагу звітувати про дані про власників замість екземплярів, щоб контролювати кардинальність. Прикладами власників екземплярів є Deployments, DaemonSets, ReplicaSets і StatefulSets, але якщо Pod не має жодного власника (standalone Pod), сам Pod звітується як власник.
- URL Path: це необроблений шлях запиту URL, як його надіслав клієнт і отримав сервер, наприклад:
/clients/348579843/command/833. - URL Route: це агрегований шлях запиту URL, семантично згрупований для контролю кардинальності. Він зазвичай імітує спосіб, яким деякі веб-фреймворки дозволяють вам визначати HTTP-запити в коді, наприклад:
/clients/{clientId}/command/{command_num}. - Operation: описує, яка функціональність була запитана:
- HTTP: всі HTTP-дії, наприклад
GET, за якими слідує маршрут URL - gRPC: шлях служби
- SQL: SQL команди, наприклад
SELECT,UPDATEабо інші команди, за якими слідує цільова таблиця - Kafka: Produce/Fetch
- HTTP: всі HTTP-дії, наприклад
- Server: це будь-який екземпляр, який отримує та обробляє HTTP або gRPC запити. Сервер також може бути клієнтом.
- Client: це будь-який екземпляр, який надсилає HTTP, gRPC, бази даних або MQ запити. Клієнт також може бути сервером.
- Service: у контексті Kubernetes це функціональність, що надається групою серверів, до яких можна отримати доступ через загальне імʼя хосту та порт.
- Endpoint: це IP-адреса або імʼя хосту та порт, які ідентифікують або сервіс, сервер, або клієнт.
- Return code: повертається кожним викликом сервісу, описує деяку метаінформацію про результат виконання. Для HTTP це коди статусу HTTP, для інших протоколів зазвичай 0 (успіх) або 1 (помилка).
Метрики рівня застосунку
Для метрик рівня застосунку ми не можемо дотримуватися простої формули множення, оскільки є кілька факторів, які впливають на кардинальність, але вони не є лінійно повʼязаними.
Наприклад, як кількість HTTP-маршрутів, так і адреси серверів збільшують кардинальність, але ми не можемо просто помножити їх, оскільки не всі екземпляри серверів приймають однакові HTTP-маршрути.
Наступна формула може надати вкрай грубе максимальне обмеження, але в наших вимірюваннях фактична кардинальність була на 2 порядки нижча за розрахунок. З цієї причини ми рекомендуємо орієнтований на вимірювання підхід, а не намагатися розрахувати кардинальність заздалегідь.
Ось список факторів, які можуть вплинути на загальну кардинальність:
- Instances: кількість інструментованих сутностей. Вони можуть бути як сервісами, так і клієнтами.
- MetricNames: кількість імен метрик рівня застосунку. Варіюється залежно від типу застосунків, які інструментує OBI. Рахуйте одну для кожної метрики, яка буде звітуватися.
- Метрики клієнтської сторони, коли OBI інструментує програми, які виконують запити до інших програм:
http.client.request.durationhttp.client.request.body.sizerpc.client.durationsql.client.durationredis.client.durationmessaging.publish.durationmessaging.process.duration
- Метрики серверної сторони, коли OBI інструментує програми, які надсилають запити з інших програм:
http.server.request.durationhttp.server.request.body.sizerpc.server.duration
- HistogramBuckets мають бути враховані та помножені на кожну метрику, оскільки кожна метрика рівня застосунку є гістограмою. Сегменти налаштовуються в OBI, але стандартно їх кількість становить 15 для метрик тривалості та 11 для метрик розміру тіла, плюс 2 додаткові метрики (сумарна гістограма та кількість).
- Operations є еквівалентом функціональності, яка викликається. У HTTP-сервісах це групує HTTP-метод і HTTP-маршрут, у RPC це імʼя методу RPC.
- Endpoints — це кількість адрес серверів і портів.
- ReturnCodes — це кількість можливих результатів операції. Зазвичай Ok/Err у gRPC або код статусу HTTP.
Приклад розрахунку
Операнди в представленій формулі кардинальності можуть перекриватися. Наприклад, інструментований клієнтський застосунок може надсилати HTTP-запити /foo і /bar, а також підключатися до обох сервісів A і B, тому:
- Operations: 2
- Endpoints: 2
Коефіцієнт Operations * Endpoints множитиме кардинальність на 4. Однак, якщо маршрут /foo є ексклюзивним для сервісу A, а маршрут /bar є ексклюзивним для сервісу B, фактичний множник кардинальності становитиме лише 2.
Коли ви розраховуєте кардинальність, встановіть оптимістичні та песимістичні межі для своїх розрахунків.
Наступний приклад ілюструє, як розрахувати кардинальність прикладної системи. Як клієнт, так і бекенд інструментовані OBI. Інші компоненти є зовнішніми:
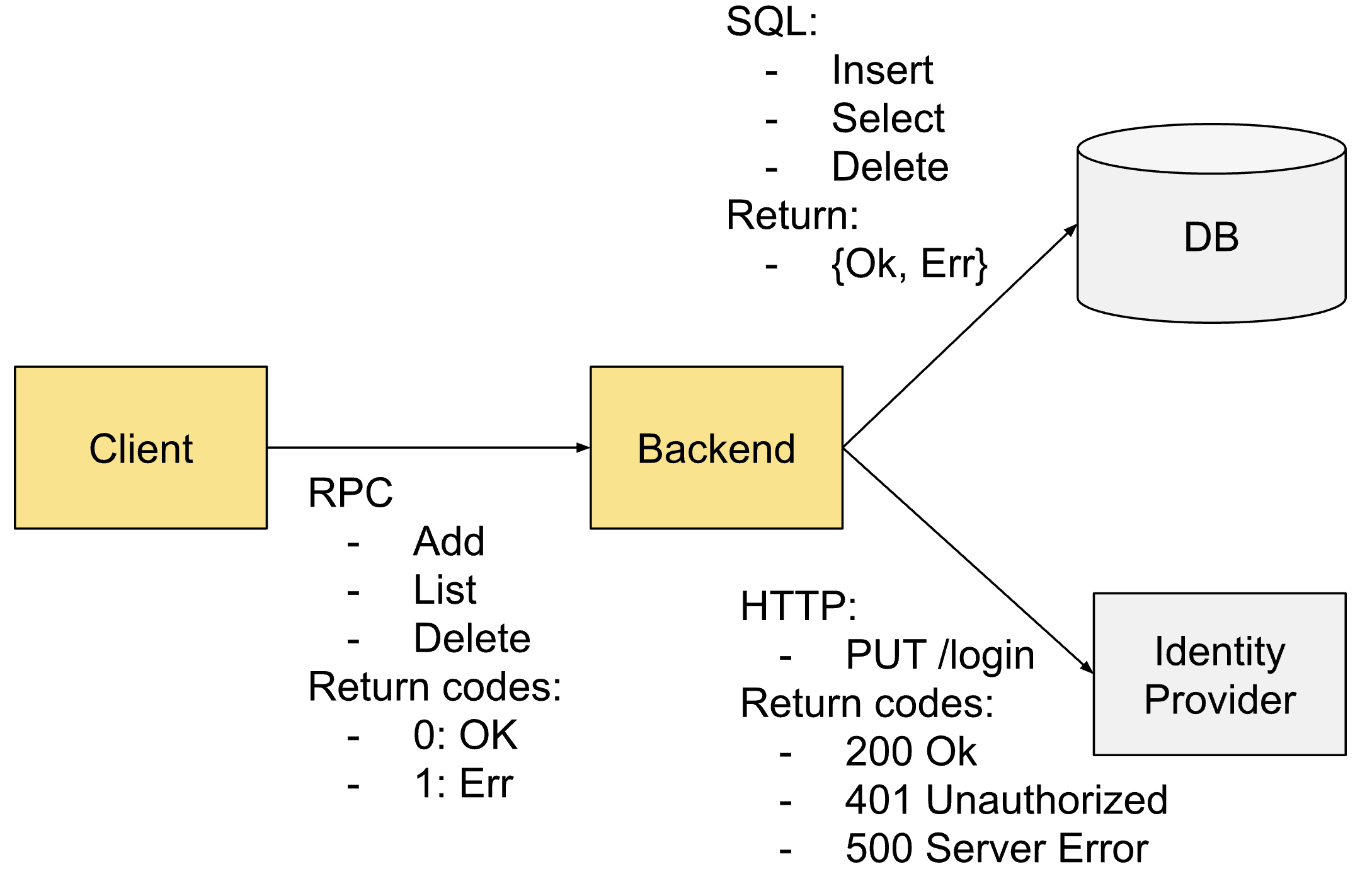
Песимістичний розрахунок буде:
#Instances * #MetricNames * #HistoBuckets * #Operations * #Endpoints * #ReturnCodes =
= 2 * 5 * 177/3 * 37/3 =2771
Цифри, взяті за основу:
- 2 екземпляри, клієнт і бекенд
- 5 типів метрик, відповідно до їхньої ролі та протоколів:
- Клієнт
rpc.client.duration
- Бекенд як RPC-сервер
rpc.server.duration
- Бекенд як SQL- і HTTP-клієнт
http.client.request.durationhttp.client.request.body.sizesql.client.duration
- Клієнт
- 17 метрик гістограм, оскільки більшість метрик базуються на тривалості
- 7 операцій: RPC Add/List/Delete, HTTP PUT, SQL Insert/Select/Delete
- 3 точки доступу: backend, Identity provider та DB
- 7 кодів повернення: RPC OK/Err, HTTP 200/401/500, SQL OK/Err
Може здатися, що кардинальність не повинна перевищувати 163. Однак це число не є реалістичним і точним, оскільки деякі множники можуть не застосовуватися до всієї системи. Наприклад, методи SQL не повинні множитися на метрики RPC і HTTP.
У цьому простому сценарії ми можемо вручну підрахувати максимальну кардинальність до 396, що значно менше, ніж початковий підрахунок 2771:
| # | Екземпляр | Метрика | Точка доступу | Операція | Код |
|---|---|---|---|---|---|
| 1 | Client | rpc.client.duration | Backend | Add | OK |
| 2 | Client | rpc.client.duration | Backend | Add | Err |
| 3 | Client | rpc.client.duration | Backend | List | OK |
| 4 | Client | rpc.client.duration | Backend | List | Err |
| 5 | Client | rpc.client.duration | Backend | Delete | OK |
| 6 | Client | rpc.client.duration | Backend | Delete | Err |
| 7 | Backend | rpc.server.duration | Add | OK | |
| 8 | Backend | rpc.server.duration | Add | Err | |
| 9 | Backend | rpc.server.duration | List | OK | |
| 10 | Backend | rpc.server.duration | List | Err | |
| 11 | Backend | rpc.server.duration | Delete | OK | |
| 12 | Backend | rpc.server.duration | Delete | Err | |
| 13 | Backend | http.client.request.duration | Identity Prov | PUT /login | 200 |
| 14 | Backend | http.client.request.duration | Identity Prov | PUT /login | 401 |
| 15 | Backend | http.client.request.duration | Identity Prov | PUT /login | 500 |
| 16 | Backend | http.client.request.body.size | Identity Prov | PUT /login | 200 |
| 17 | Backend | http.client.request.body.size | Identity Prov | PUT /login | 401 |
| 18 | Backend | http.client.request.body.size | Identity Prov | PUT /login | 500 |
| 19 | Backend | sql.client.duration | DB | Insert | OK |
| 20 | Backend | sql.client.duration | DB | Insert | Err |
| 21 | Backend | sql.client.duration | DB | Select | OK |
| 22 | Backend | sql.client.duration | DB | Select | Err |
| 23 | Backend | sql.client.duration | DB | Delete | OK |
| 24 | Backend | sql.client.duration | DB | Delete | Err |
Для стислості ми не підраховували сегменти гістограми. Далі ми помножуємо екземпляри метрик на сегменти гістограми, додаємо гістограму _count та _sum:
- 3 екземпляри метрик розміру тіла x 13 = 39
- 21 екземпляр метрик тривалості x 17 = 357
Загальна кардинальність: 396
Вищезазначений приклад ілюструє, що важко надати одну формулу для обчислення впливу кардинальності. Нам вдалося підрахувати точну кардинальність дуже простого прикладу, де вся інформація відома. Цю вправу було б неможливо виконати в великому кластері Kubernetes, де ми маємо мало або жодної інформації про застосунки та їх взаємозвʼязки.
Метрики мережевого рівня
Обчислювати метрики мережевого рівня простіше, ніж метрики рівня застосунків, оскільки OBI надає лише один лічильник: obi.network.flow.bytes. Однак кардинальність також залежить від того, наскільки ваші програми взаємоповʼязані.
Стандартні значення для obi.network.flow.bytes:
- Напрямок (запит/відповідь)
- Власники точок доступу джерела та призначення в Kubernetes:
k8s_src_owner_name,k8s_dst_owner_name,k8s_src_owner_type,k8s_dst_owner_type,k8s_src_namespace,k8s_dst_namespace k8s_cluster_name: унікальний для кожного кластера. Ми припускаємо, що для решти метрик єдиний кластер.
Спрощена, песимістична формула виглядає так:
#Directions * #SourceOwners * #DestinationOwners
Ми припустили, що всі власники джерел підключені до всіх власників призначення. Більш реалістично застосувати фактор звʼязку, наприклад, кластер з 100 Deployments/DaemonSets/StatefulSets, де кожен власник підключений в середньому до 2 інших власників, матиме кардинальність:
2 напрямки x 100 ВласниківДжерела x 2 ВласниківПризначення = 400
Метрики Service Graph
Метрики Service Graph генеруються для екземплярів, які можуть бути інструментовані метриками застосунків, наприклад HTTP, RPC, SQL, Redis і Kafka. Мережеві метрики генеруються для будь-якого екземпляра з мережевим трафіком, незалежно від використовуваного протоколу.
Метрики Service Graph виробляють такі метрики:
traces_service_graph_request_client: гістограма з 15 сегментамиtraces_service_graph_request_server: гістограма з 15 сегментамиtraces_service_graph_request_failed_total: лічильникtraces_service_graph_request_total: лічильник
Кожна метрика також має такі атрибути:
source: obiclientтаclient_namespaceserverтаserver_namespace
Обчислення подібне до мережевих метрик, але з вищою кардинальністю:
- Замість одного лічильника метрик ми звітуємо про набір метрик/гістограм з загальною кардинальністю 36, по дві 15+2 гістограми + 2 лічильника.
- Замість агрегації за власником екземпляра, наприклад Deployment, клієнт — це екземпляр, який надсилає запит, тоді як сервер може бути Власником, оскільки до нього зазвичай звертаються через єдиний екземпляр служби.
Метрики Span
traces_spanmetrics_latency: гістограма з 15 + 2 сегментамиtraces_spanmetrics_calls_total: лічильникtraces_spanmetrics_size_total: лічильникtraces_spanmetrics_response_size_total: лічильник
Атрибути, які можуть додати кардинальність до кожної метрики:
- Service/ServiceNamespace/Instance ID
- Span Kind: Client/Server/Internal
- Span Name: зазвичай назва операції і може мати високу кардинальність
- Коди повернення
Максимальна кардинальність може бути приблизно розрахована як:
19 metric buckets * 3 span kinds * #Instances * #Operations * #ReturnCodes
Як показано у попередньому прикладі розрахунку для метрик застосунків, ми припустили, що велика кількість кодів повернення HTTP множитиметься лише на служби HTTP, або що деякі групи екземплярів матимуть лише підмножину загальних маршрутів.
Приклад використання: кардинальність OpenTelemetry Demo
У цьому розділі ми розраховуємо кардинальність OpenTelemetry Demo, розгорнутого в локальному кластері з 3 вузлів. Ми вимкнули всі вбудовані інструменти OpenTelemetry в демонстраційних застосунках і розгорнули OBI для виконання інструментації.
Оцінка метрик на рівні застосунків
Оскільки більшість інструментованих екземплярів є як клієнтами, так і сервісами, ми ігноруємо аргумент #instances у формулі для більшої точності:
#MetricNames * (#HistoBuckets+2) * #Operations * #Endpoints * #ReturnCodes
Для зменшення впливу атрибутів, які впливають нелінійно на остаточну кардинальність, ми розраховуємо значення кардинальності для всіх типів метрик окремо (HTTP, gRPC і Kafka).
Метрики HTTP:
- 4 метрики: клієнт, сервер, розмір запиту та час
- В середньому 15 сегментів гістограм
- Відомі операції: 75, виміряні з працюючого OTel Demo за допомогою запиту PromQL:
group by (http_request_method, http_route)({__name__=~"http_.*"}) - 26 endpoints, виміряні з працюючого OTel Demo за допомогою запиту PromQL:
group by (server_address, server_port)({__name__=~"http_.*"}) - 6 кодів статусу відповіді: 200, 301, 308, 403, 408 і 504, витягнуті з працюючого OTel demo
В підсумку, максимальний розрахунковий ліміт для HTTP метрик становить:
4 x 15 x 75 x 26 x 6 =~ 702,000
Це показує, наскільки неефективною є формула для метрик на рівні застосунків, оскільки виміряне число значно нижче, навіть для всіх відомих типів метрик застосунків:
count({__name__=~"http_.*|rpc_.*|sql_.*|redis_.*|messaging_.*"}) → 9,600
Оцінка метрик на рівні мережі
Для метрик на рівні мережі, якщо ми припустимо 2 напрямки (запит/відповідь) і 21 розгортання, які запитують інформацію у всіх 21 розгортаннях, ми отримуємо такі числа кардинальності:
2×21×21 = 882
Знаючи архітектуру, ми могли б отримати нижчу оцінку, якщо б ми враховували лише стрілки на діаграмі архітектури і припустили, що вони представляють обидва напрямки:
2x29 = 58
Метрики мережі вимірюють зʼєднання OpenTelemetry Demo, інші внутрішні зʼєднання кластера та трафік інструментації, тому реальна кардинальність є вищою:
count(obi_network_flow_bytes_total) → 330
Ми можемо згрупувати трафік між просторами імен, щоб отримати краще уявлення про те, яка частина належить до OpenTelemetry demo, за допомогою наступного запиту:
count(obi_network_flow_bytes_total) by (k8s_src_namespace, k8s_dst_namespace)
Що повертає наступну інформацію:
| k8s_src_namespace | k8s_dst_namespace | count |
|---|---|---|
| default | default | 156 |
| kube-system | default | 47 |
| default | kube-system | 47 |
| default | 14 | |
| default | 14 | |
| kube-system | 13 | |
| kube-system | 13 | |
| gmp-system | 3 | |
| gmp-system | 3 | |
| default | gmp-system | 1 |
| gmp-system | default | 1 |
Кількість мережевих метрик, згенерованих демонстрацією OpenTelemetry для трафіку між компонентами Демо, становить 156. Простір імен default є як джерелом, так і призначенням. Є й інший трафік до kube-system, gmp-system або взагалі без простору імен, який належить зовнішнім зʼєднанням, телеметрії або управлінню Kubernetes.
Оцінка Service Graph метрик
Метрики мережі часто використовуються для побудови service graphs, але фактичні метрики матимуть іншу структуру:
- Замість однієї метрики лічильника у нас є 2 метрики лічильника та ще 2 метрики з гістограмами з 16+2 сегментами.
- Метрики service graphs зазвичай ігнорують внутрішній трафік Kubernetes або будь-який трафік з екземплярів, які не мають інструментації на рівні застосунків.
Виміряне число:
count({__name__=~".*service_graph.*"}) → 2300
Оцінка метрик відрізків
Вимірювання метрик на рівні застосунків показало, що отримати аналітичне число було важко через велику кількість залучених параметрів. Ми можемо отримати правильне вимірювання кардинальності, вимірюючи його за допомогою PromQL:
count({__name__=~".*spanmetrics.*"}) → 3900
Відгук
Чи це було корисним?
Дякуємо. Ми цінуємо ваші відгуки!
Будь ласка, дайте нам знати як ми можемо покращити цю сторінку. Ми цінуємо ваші відгуки!